Deployment Modes
Deployment Modes
Monolithic mode
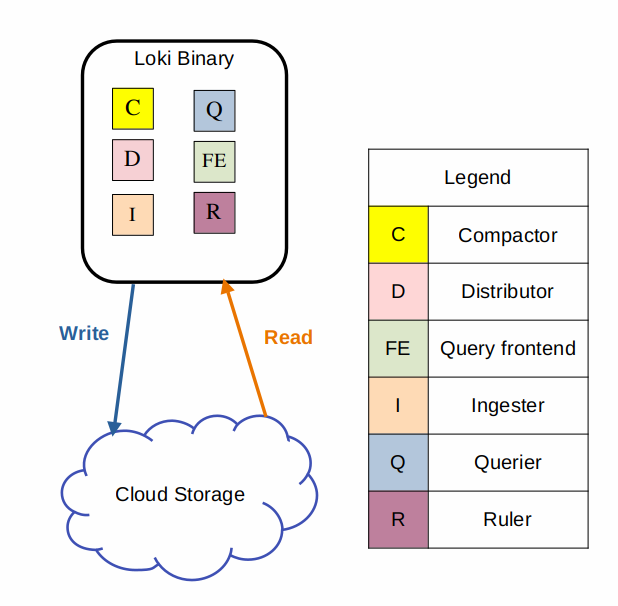
- All components (distributor, ingester, querier, compactor, etc.) run in a single process
- Will work up to ~20GB/day
- Can be horizontally scaled by adding instances to the ring cluster — requires shared object storage
- Good for: local docker-compose setup, dev/test environments, small projects
- Simplest to configure — one
values.yamlfile, one deployment - Drawback: no ability to independently scale individual components (e.g., you cannot add just ingesters)
Simple Scalable
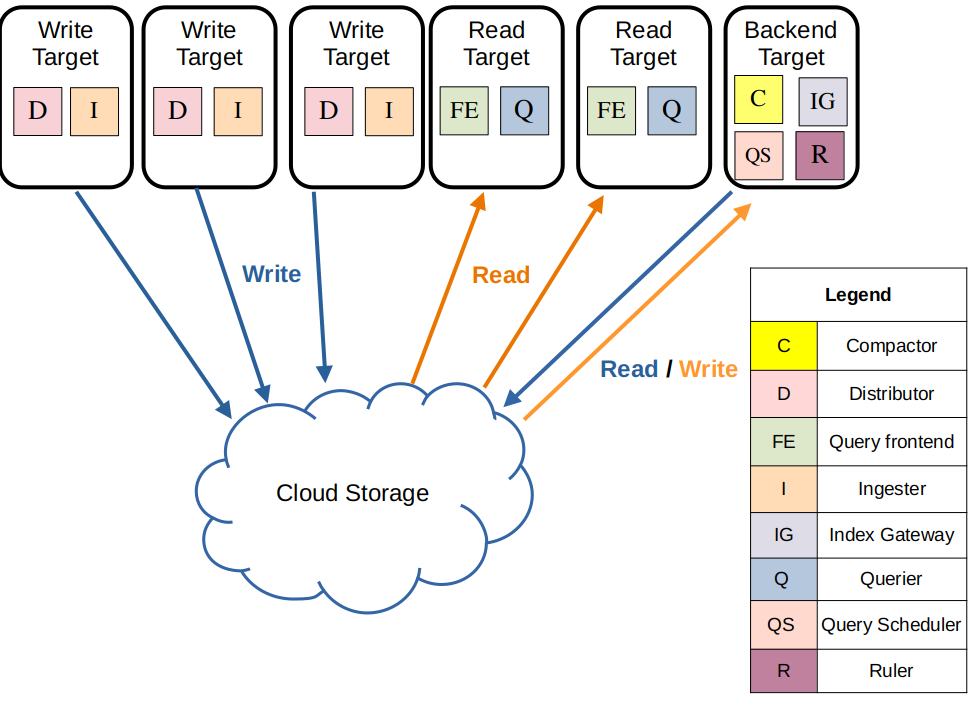
Simple Scalable Deployment (SSD) mode is being deprecated. The timeline for the deprecation is to be determined (TBD), but will happen before Loki 4.0 is released.
- Default deployment mode (since Loki 3.0)
- Three targets: read, write, and backend
- write — distributor, ingester
- read — query frontend, querier
- backend — compactor, ruler, index gateway, bloom gateway
- Can handle up to several TB/day. Above that, microservices mode is recommended
Microservices mode
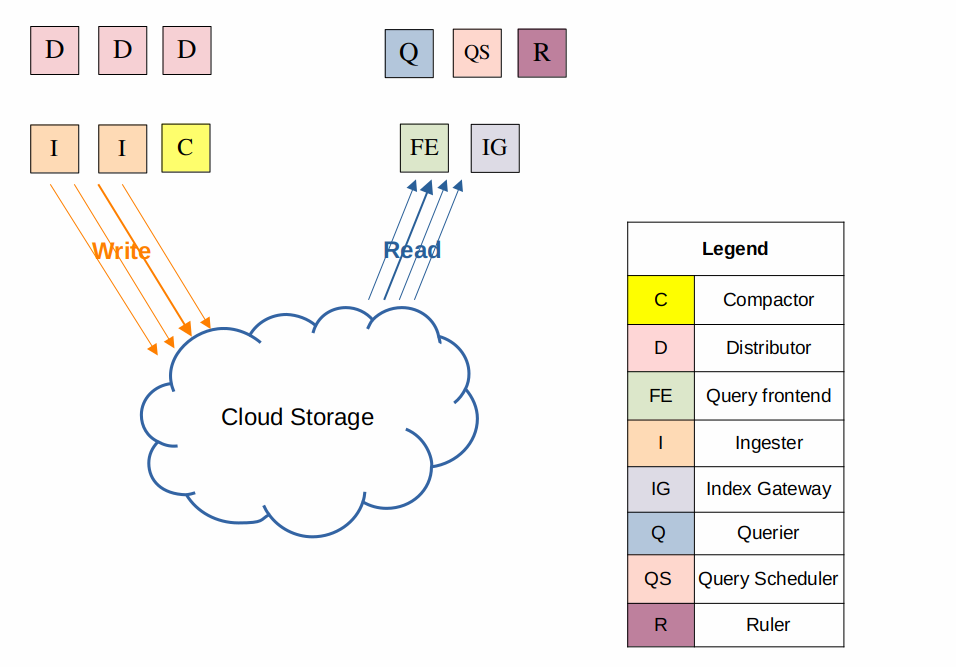
- Microservices mode
- Each component (distributor, ingester, querier, query-frontend, compactor, ruler, index-gateway) runs as a separate deployment/service
- Full control over scaling — each component scaled independently (e.g., more ingesters during peak hours)
- Recommended for volume > several TB/day or when precise resource control is required
- Drawback: significantly more complex configuration and maintenance — requires knowledge of each component
- In practice, mainly used by large organizations (e.g., Grafana Cloud)
This workshop’s current deployment: Distributed (microservices) mode — see
helm_values/loki/loki.values.template.yaml.
Auto-Scaling Best Practices
Loki is designed for horizontal scaling. In microservices and Simple Scalable modes, individual components can be auto-scaled with Kubernetes HPA or KEDA.
Which Components to Auto-Scale
| Component | Auto-scalable? | Scale trigger | Notes |
|---|---|---|---|
| Distributor | ✅ Yes | CPU, incoming request rate | Stateless — scale freely |
| Ingester | ⚠️ With care | Memory, active streams | Stateful — uses ring, needs graceful scale-down. Set ingester.lifecycler.min_ready_duration and ensure ring rebalancing completes before terminating pods |
| Querier | ✅ Yes | CPU, query queue depth | Stateless — scale based on query load |
| Query Frontend | ⚠️ Rarely needed | — | 2 replicas usually enough — it splits queries, doesn’t execute them |
| Compactor | ❌ No | — | Singleton — only one instance should run |
| Ruler | ✅ Yes | Number of rules/tenants | Stateless, uses ring for rule sharding |
| Index Gateway | ✅ Yes | CPU, query latency | Stateless, caches index data |
HPA Examples
Distributor — scale on CPU:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: loki-distributor
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: loki-distributor
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Querier — scale on custom metric (queue length):
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: loki-querier
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: loki-querier
minReplicas: 2
maxReplicas: 15
metrics:
- type: Pods
pods:
metric:
name: cortex_query_scheduler_queue_length
target:
type: AverageValue
averageValue: "5"
Ingester Scaling — Special Considerations
Ingesters are stateful (hold data in memory before flushing). Improper scaling can cause data loss or ring instability.
Safe scale-up:
- New ingesters join the ring automatically via memberlist/gossip
- The ring rebalances token ownership — some streams will move to new ingesters
Safe scale-down:
- Ingester must flush all chunks to storage before shutting down
- Set
terminationGracePeriodSecondshigh enough (e.g., 300s) - Use
preStophook or Loki’s built-in shutdown procedure (/ingester/shutdown) - Never scale down more than one ingester at a time — wait for ring stabilization between removals
# Pod spec for ingesters
terminationGracePeriodSeconds: 300
lifecycle:
preStop:
httpGet:
path: /ingester/shutdown
port: http-metrics
Key Metrics for Auto-Scaling Decisions
# Distributor — incoming volume
rate(loki_distributor_bytes_received_total[5m])
# Ingester — memory pressure (primary constraint)
loki_ingester_memory_streams
# Querier — query load
cortex_query_scheduler_queue_length
# Overall write path health
rate(loki_request_duration_seconds_count{route="loki_api_v1_push"}[5m])
General Guidelines
- Start with fixed replicas, observe usage patterns, then add HPA
- Set
minReplicas≥ 2 for all stateless components to maintain availability during scale events - Avoid scaling ingesters to 0 — data in memory will be lost
- Use PodDisruptionBudget — especially for ingesters (
maxUnavailable: 1) - Scale the write path and read path independently — log ingestion spikes don’t necessarily correlate with query load
- Monitor ring health after scaling events:
cortex_ring_membersmetric